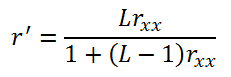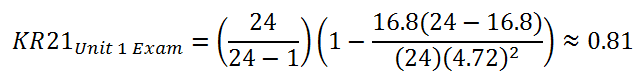Introduction
This article shows an easy way to estimate the reliability of selected-response (multiple-choice and numerical-response) tests by using Kudar and Richardson Fromula 21 (KR21). This methodology is applied to Mathematics 30-1 Unit 1 Exam Form A and Form B. A spreadsheet is provided that implements KR21 to easily estimate the reliability of a set of test scores. The reliabilities of the scores produced by Form A and B are very high. Colloquially, these exams could be said to be “very reliable exams.” However, in truth, exams cannot be reliable: only the score sets they produce can be so. This is because a certain exam may produce reliable results for one population, and yet produce quite unreliable results for another. In this article, the on-campus and online populations are being treated as one population, under the assumption that both are very similar; however, I have no statistics to justify this.
Background
In 2012, I created four unit exams for Mathematics 30-1. For a year, these were the only Mathematics 30-1 unit exams in existence in our department. Since then, Debbie Scott has cloned them to produce Form B’s. Were the Form A’s worthy of being cloned? Are they cultivars with desirable characteristics? In Methodologies for Evaluating the Validity of Scores Produced by CEFL’s Equivalency Exams, I looked at the criterion-referenced validity of the unit exams by comparing class scores to diploma exam scores. The criterion-referenced validity of the scores collectively produced by the unit exams is very high. On a practical level, this means that the rank order of student performance on the unit exams is largely repeated on the diploma exam. If the rank order of scores on the unit exams from lowest to highest is Vera, Chuck, and Dave (The Beatles, 1963), then the rank order of scores on the diploma exams will also likely be Vera, Chuck, and Dave. Carefully propagating the form A Mathematics 30-1 unit exams will likely produce new forms that also produce valid scores--this on the assumption that the diploma exam is itself the most valid measure of ability in the course.
In this article, I look at the reliabilities of individual unit exams (rather than the validities of the class scores) as a next step in building a validity argument that supports the validity of the scores they produce.
Kudar and Richardson Formula 21 (KR21)
This article investigates the reliability of Unit 1 Exam Form A and Unit 2 Exam Form A using a simple method. Complex item-analysis software is not required to derive this statistic (however, item-analysis provides useful information about the reliability of individual items). I employed Google Spreadsheets to estimate reliability using Kudar-Richardson Formula 21 (KR21):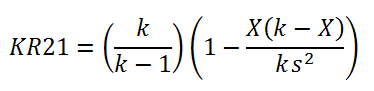
where k is the number of items on the exam, X is the mean of the raw scores, and s is the standard deviation of the raw scores. Raw scores--not percentage scores--must be used to produce the statistics that are put into this formula. Zeroes for students who missed the exam must not be included, else the reliability will be spuriously inflated. This formula is easy to use because the only data we need are the students’ raw scores. As long as the exam is entirely composed of selected-response items (multiple-choice or numerical-response items), then this formula will provide an estimate of the reliability statistic. Scores on written-response items cannot be used because they are usually polytomously scored, i.e., they are not marked as entirely correct or entirely incorrect as selected-response items are. And because KR12 always underestimates reliability, we can be confident that the true reliability is at least as large as the value produced by KR21.
Reliability and Validity
Violato (1992) provides some general guidelines for evaluating the reliabilities of teacher-made tests: 0.50 or greater is acceptable, and 0.70 or greater is excellent. Tests produced by professional testing agencies should have reliabilities of at least 0.80, which means that 80% of the variation in observed scores is caused by real differences in ability, and 20% of the variation is caused by errors in measurement--essentially, 20% of the variation in the test-takers’ scores is just noise and tells us nothing about students’ relative abilities. Please refer to the first half of Methodologies for Evaluating the Validity of Scores Produced by CEFL’s Equivalency Exams for a more detailed exploration of reliability and validity.
Spearman-Brown Prophesy Formula
A test composed of more items produces results that have more reliability than the scores produced by shorter tests. All items produce a signal and some noise. The net signal indicated by the test scores tends to become more salient than the noise as more items are added. This is because pure noise tends to cancel itself out and is not additive in the sense that noise plus noise usually equals about the same amount of noise, whereas signal plus signal typically results in more signal. This holds as long as the items are in phase, i.e., each item tells us a little bit about a student’s ability in a certain subject matter. Item analysis can tell show us which items are in phase and which are out of phase with the other items. We can eliminate the out of phase items to boost the reliability of the test scores, or we can accept an out of phase item on the premise that many subject areas are not perfectly homogeneous, as long as the item tests something important. In other words, certain items may march to the beat of their own drummer because the skills they legitimately test are largely unrelated to the other content in the course, which sometimes happens.
Increasing the number of items on a test usually increases validity because reliability sets the upper limit of validity. Furthermore, more items usually means a greater variety of samples are taken from the content domain, thus increasing content validity.
Because our unit exams are shorter than diploma exams, we would expect them to produce less reliable results than diploma exams. To be fair to our unit exams, we need a way of comparing apples to apples. The Spearman-Brown Prophesy Formula foretells (prophesies) the reliability of an equivalent exam with a different length:
(Violato, 1992)
where L is the ratio of the number of items in the new test divided by the number of items in the original test; rxx is the reliability of the original exam; and r’ is the reliability of the new exam.
For instance, let us say that the reliability of the scores produced by a certain 24-item unit exam is 0.70, a respectable enough statistic in itself. What would the reliability of the scores produced by a 40-item diploma exam be if it was constructed from items of the same quality as those used in the 24-item unit exam? Given that the ratio, L, is 40/24 = 1.6 repeating and rxx=0.70, then:
Increasing the length of a 24-item exam by about 67% increases its reliability from 0.70 to 0.79. This estimate is useful because it can help to answer the question “Is it worthwhile to lengthen this exam? Is the improved precision of the results worth the temporal and monetary costs of a longer exam? Could those temporal and monetary resources be better employed elsewhere?” Of course, the answer is “it depends.”
The Reliability of Mathematics 30-1 Unit 1 Exam Form A (“Transformations and Functions”)
Since the Mathematics 30-1 unit exams were first implemented in Anytime Online, I have recorded the student scores (ID number, date, and score) for each exam. Debbie Scott provided me with several student scores on the unit exams in Trad. The following statistics are based on these data. To estimate the reliability of a selected-response test, all we need are the students’ raw scores. After one or two terms, we would usually have enough data.
The Mathematics 30-1 Unit 1 Exam Form A is out of 24 points. Here are the relevant statistics based on 76 student records:
maximum possible raw score (k) = 24
standard deviation (s) = 4.72
mean (X) = 16.8 (70%)
The above statistics are easily calculated using a Google or Excel spreadsheet, or even a TI-84 calculator.
According to KR21, the reliability of the Mathematics 30-1 Unit 1 Exam Form A is:
A reliability coefficient of 0.81 is very good. We can have some faith in this statistic because it is based on 76 student records. But what if items of the same quality were used to construct a 40-item exam? This hypothetical reliability can be prophesied thus:
If the Unit 1 Exam Form A was extended to 40 items, its reliability coefficient would be 0.87. The reliability coefficient of the January 2013 Mathematics 30-1 diploma exam is estimated to be 0.90 by employing KR21. Unit 1 Exam Form A compares very well to the Mathematics 30-1 diploma exam in terms of the reliability of the score set it produces. This indicates that the items that compose the Unit 1 Exam are of a similar quality to the items that compose the diploma exam.
The Reliability of Mathematics 30-1 Unit 2 Exam Form A (“Trigonometry”)
The Mathematics 30-1 Unit 2 Exam Form A is out of 24 points. Based on 48 student records from ATOL and Trad, here are the relevant statistics:
maximum possible raw score (k) = 24
standard deviation (s) = 5.59
mean (X) = 15.4 (64%)
According to KR21, the reliability of the Mathematics 30-1 Unit 2 Exam Form A is:
A reliability coefficient of 0.86 is impressive. Let’s see what the coefficient would be if this exam was lengthened to 40 items: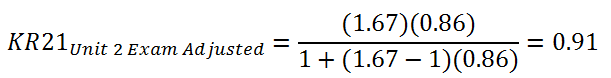
The reliability of a 40-item test composed of items of a similar quality as those used in Unit 2 Exam is prophesied to be 0.91. The items that compose Unit 2 Exam are of a similar degree of quality as the items that compose the January 2013 Mathematics 30-1 diploma exam.
Spreadsheet for Easily Calculating Reliability Using KR21
The test scores in this spreadsheet are for illustration only. Delete these scores and enter the raw scores for one of your own exams. Note that if a student misses an exam and scores zero on that exam, then that score must NOT be entered because it would spuriously increase the reliability coefficient because it would spuriously increase the standard deviation; in other words, only the scores of bona fide test-takers are to be included. Blank cells are ignored.
Conclusion and Next Steps
Mathematics 30-1 Unit 1 Exam Form A and Mathematics 30-1 Unit 2 Exam Form A produce results that can be relied upon. Thus, in this respect, they are worthy of being cloned to produce version B exams. These exams are composed of high-quality items in terms of the reliability of the results they produce. Applying the Spearman-Brown Prophesy Formula allows us to compare the results produced by our unit exams to the longer diploma exams on an equal footing.
In a future article, I would like to discuss the limitations of the information provided by the reliability statistic. Statistics can be used to aid in making predictions and evaluations; however, as always, “it depends.”
Regards,
Michael
References
Violato, C., McDougall, D., & Marini, A. (1992). Educational Measurement and Evaluation. Dubuque: Kendall/Hunt.